GPS – Les risques de brouillage et de leurrage expliqués

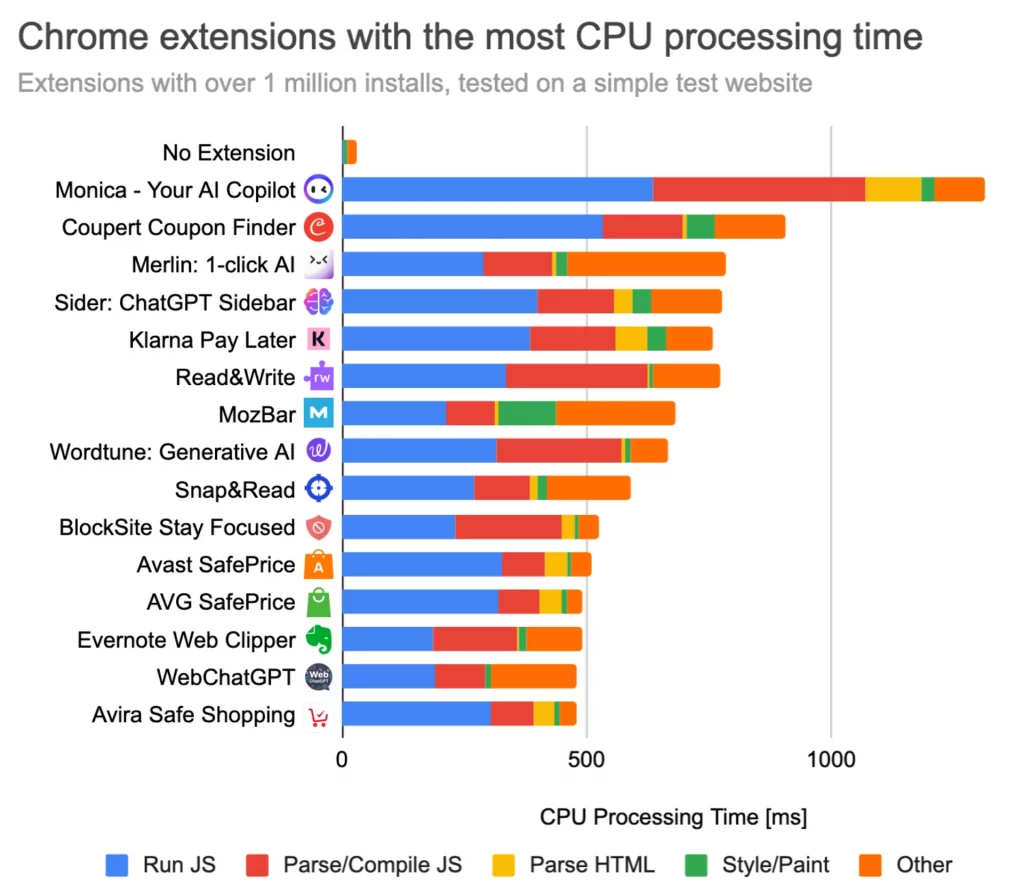
Vous utilisez probablement le GPS tous les jours sans y penser, que ce soit sur votre smartphone, dans votre voiture ou même dans un avion. Cette technologie de positionnement par satellites, et ses cousines comme GLONASS, Galileo et Beidou, sont devenues tellement courantes qu’on en oublierait presque qu’elles sont vulnérables. Et quand je dis vulnérables, je ne parle pas d’un bug ou d’un plantage logiciel, non. Je parle de menaces bien réelles qui peuvent rendre votre GPS complètement dingue !
Vous voyez, le GPS repose sur des signaux radio ultra faibles émis par des satellites à des milliers de kilomètres. Pour vous donner une idée, c’est un peu comme si vous essayiez d’entendre quelqu’un vous chuchoter quelque chose depuis l’autre bout d’un stade pendant un concert de rock ! Autant dire que c’est le bordel pour entendre quoi que ce soit.
Du coup, pas besoin d’être un génie pour comprendre qu’il est facile de noyer le signal GPS dans un gros brouhaha radio. C’est ce qu’on appelle le brouillage. Avec quelques watts seulement, on peut rendre le GPS inutilisable dans un rayon de plusieurs kilomètres ! Pas besoin d’un doctorat en électronique, un petit bricolage fait maison peut suffire. Évidemment, c’est complètement illégal, mais ça n’empêche pas certains de s’amuser à le faire.
Mais pourquoi brouiller le GPS ? Eh bien, en cas de conflit par exemple, c’est bien pratique pour empêcher l’ennemi de savoir où il est et où tirer ses missiles et ses drones. C’est d’ailleurs ce qui se passe en ce moment autour de l’Ukraine. Des zones de brouillage apparaissent régulièrement, rendant la navigation aérienne hasardeuse.
Mais le brouillage peut aussi servir à des fins moins guerrières. Tenez, en Chine, il paraît que des boîtes de pub brouillent le GPS des drones de leurs concurrents pendant des shows aériens pour leur faire perdre le contrôle et ruiner le spectacle ! De la concurrence de haut vol, sans mauvais jeu de mots.
Et les dégâts collatéraux dans tout ça ?
Parce que mine de rien, on ne dépend pas du GPS uniquement pour savoir si on doit tourner à gauche ou à droite au prochain croisement. Les réseaux de téléphonie mobile s’en servent également pour synchroniser leurs antennes relais. Ainsi, quand le GPS déconne, c’est toute la 4G/5G qui peut partir en vrille !
Mais si vous trouvez que le brouillage c’est déjà costaud, attendez de découvrir le leurrage ! Là, on passe au niveau supérieur. Le leurrage, c’est carrément une technique qui permet d’envoyer de faux signaux GPS pour faire croire à votre récepteur qu’il est ailleurs. Un peu comme si un petit rigolo changeait les panneaux sur la route pour vous faire croire que vous allez vers le sud de la France, alors que vous roulez vers le Nord.
Alors bien sûr, générer un faux signal GPS crédible, c’est autrement plus coton que simplement brouiller la fréquence. Il faut recréer toute une constellation de satellites virtuels avec les bons timings, les bonnes orbites, cohérents entre eux. Un vrai boulot d’orfèvre ! Mais une fois que c’est au point, imaginez le potentiel de nuisance ! Vous pourriez faire atterrir un avion de ligne à côté de la piste. Téléguidez un drone militaire en territoire ennemi ou envoyer un navire s’échouer sur des récifs. Ça fait froid dans le dos…
Heureusement, il existe des parades pour durcir les récepteurs GPS contre ces attaques : Utiliser des antennes directionnelles qui filtrent les signaux ne venant pas du ciel. Analyser en détail les signaux pour repérer les incohérences et les satellites suspects. Recouper avec d’autres capteurs comme les centrales inertielles. La version militaire du GPS dispose déjà de pas mal de protections dont du chiffrement.
Mais pour le GPS grand public dans nos smartphones et nos bagnoles, on est encore loin du compte. À part quelques modèles haut de gamme, la plupart gobent à peu près tout et n’importe quoi tant que ça ressemble à un signal GPS et il va falloir que ça change, et vite !
Scott Manley, un expert en la matière que vous connaissez peut-être pour ses vidéos sur les fusées, aborde en profondeur ces questions dans une vidéo bien documentée sur le sujet. Non seulement il analyse les risques de brouillage et de leurrage, mais il examine aussi les contre-mesures possibles, comme l’utilisation d’antennes directionnelles et l’analyse détaillée des signaux pour repérer d’éventuelles incohérences. Je vous mets la vidéo ici, ça vaut le coup d’œil :
On a beau être fan des nouvelles technos qui nous rendent la vie plus facile, faut quand même garder à l’esprit qu’elles ont leurs failles et leurs limites. Ça ne veut pas dire qu’il faut revenir à la bonne vieille carte Michelin et à la boussole, mais un petit cours de rattrapage en navigation à l’ancienne, ça ne ferait pas de mal !
Perso, la prochaine fois que mon appli Waze me dira de tourner à gauche direct un lac, je me méfierai…